 A Theory of Stuttering
A Theory of Stuttering
A Theory of Stuttering
The self-monitoring of speech (henceforth often simply referred to as monitoring) is not only a mechanism that allows us to check whether words, phrases, and sentences have been produced correctly and according to the intended message. Automatic self-monitoring also includes the online adjustment of volume, pitch, rate, and articulatory distinctness. However, I do not assume that these online-adjustments play a role in the causation of stuttering; therefore, it is not the topic here (read more). I will only deal with that part of self-monitoring that serves for the detection and repair of speech errors.
As already pointed out in Section 1.1, the self-monitoring responsible for error detection is also a mechanism ensuring that the next speaking program (speech motor program) can only start if the previous speech unit is correct and complete. Therefore, this kind of monitoring is relevant for speech fluency, namely in a negative sense: the monitoring system interrupts speech flow immediately after it has detected an error, more precisely, a mismatch between the correct sound sequence expected and the sound sequence actually produced and perceived. This part of self-monitoring will play a crucial role in the theory of stuttering proposed on this website.
In his Perceptual Loop Theory, Levelt (1995) distinguishes between an external and an internal feedback loop (see figure). Hearing one’s own speech through the ears is referred to as external feedback. Internal feedback is the internal perception of one’s speech, e.g., in silent reading and verbal thinking (see Section 1.5). We can also use the internal feedback loop to check an intended formulation before we speak it out. However, this conscious ‘pre-articulatory monitoring’ is merely a kind of verbal thinking; we use it in situations where we shouldn’t say something wrong (read more). Lind et al. (2014) demonstrated that we normally monitor our speech using the external feedback loop: we know what we have said by hearing it.
Both feedback loops, the external and internal one, provide sensory feedback in the auditory modality. This is obvious for the external feedback of speech, but the internal feedback of speech is feedback in the auditory modality as well, an ‘inner hearing’. In addition to auditory feedback, tactile and kinesthetic feedback of speech movements are not unimportant for the control of articulation. Sometimes, these kinds of sensory feedback may play a role in the detection of phonological speech errors, particularly if voiceless consonants are involved. But I do not assume that tactile and kinesthetic feedback play any role in the causation of stuttering, and they are mentioned here only for the sake of completeness.
Let us return to the two auditory feedback loops. A question crucial to the present theory of stuttering is whether external and internal auditory feedback are available at the same time. This is not the case. In a behavioral study, Smith, Reisberg, and Wilson (1992) found that the use of internal auditory feedback was the more disrupted, the more a concurrent external auditory input was phonologically similar to what should be heard internally. White noise did not impair the use of internal auditory feedback, but externally presented speech stimuli blocked it. From this, it follows that the external auditory feedback blocks the internal one because both are phonologically the same.
A further argument against the concurrency of external and internal AF comes from Vigliocco and Hartsuiker (2002): if internal and external AF worked concurrently, we would hear ourselves twice with a time lag between the two signals because they need different time (Lackner & Tuller, 1979). Moreover, the Lee Effect would not occur if internal auditory feedback compensated for the problems in speech control caused by delayed external auditory feedback (read more).
We can thus assume that both feedback loops work alternately. Internal auditory feedback is only available when one’s own speech is externally inaudible. This is the case during inner speech (verbal thinking), ‘mouthing’ (silent speech movements, also referred to as ‘lipped speech’ or ‘pantomime speech’ ), with complete auditory masking, or with hearing loss. Interestingly, stuttering mostly disappears in all these conditions, and the theory proposed in the next chapter will explain this remarkable phenomenon.
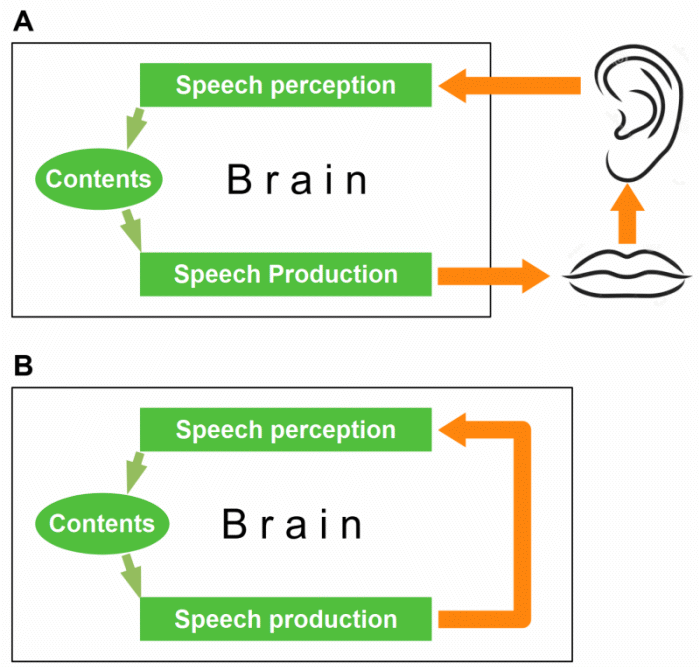
Figure 3: External feedback loop, e.g., in speaking aloud (A), and internal feedback loop, e.g., in verbal thinking (B).
Figure 3 shows my model of speech processing and self-monitoring. It differs from Levelt’s model in two points, which are closely related to one another: I don’t assume that formulation and articulation are separate in the brain (see here for the reason) and that inner speech is a phonetic plan for overt speech.
Usually, the self-monitoring of speech is regarded as a mechanism mainly serving to detect speech errors (slips of the tongue). The correctness of a spoken word, however, logically includes its completeness. Hence, self-monitoring plays an important role in speech acquisition, namely in learning to articulate every word completely up to its end before the next word is started, and not to clip the last sounds or the last syllable of a word or phrase. This function of monitoring appears to be redundant once correct and complete articulation has been automated. However, as I will explain later, just this partial function of monitoring possibly plays a crucial role in the causation of stuttering.
The crucial differences between monitoring physical features of speech such as volume, pitch, or rate, on the one hand, and monitoring for the purpose of detecting speech errors, on the other hand, is the type of reaction. Volume, pitch, rate, and also the distinctness of articulation can be adjusted online, without interruption of speech flow. The repair of a speech error, in contrast, takes place offline; that is, speech flow needs to be interrupted. Furthermore, the adjustment of volume, pitch, or rate does not require understanding the words spoken. This is also true for the self-monitoring of articulation as far as it only concerns the distinctness of vowels and consonants, that is, the avoidance of mumbling. The detection of a speech error, in contrast, requires understanding the spoken words and knowing how the correct word has to sound.
I do not assume that the self-monitoring of volume, pitch, rate, or articulation plays a role in the causation of stuttering, although some stutterers seem to have difficulty controlling volume or rate; they tend to speak too rapidly or too low. The latter may either result from low self-confidence because of stuttering or from acoustic oversensitivity (see Section 3.3).
The former, speaking too rapidly, has often been suspected to elicit stuttering because of the observation that slow speech mostly reduces stuttering. But the fluency-inducing effect of slow, prolonged speech is mainly caused by audio-phonatory coupling, which ensures that speech motor control cannot decouple from auditory feedback (read more in Section 3.4). A high speech rate and the inability to pause between clauses and units of meaning may also be a result of stuttering in some cases, namely of lacking courage to keep listeners waiting.
(return)
Levelt (1995) described the relationship between both the feedback loops as follows:
Internal auditory feedback is not available here because internal and external auditory feedback would phonologically be the same, despite the delay of the latter. This explains the seemingly paradoxical fact that normal speakers are disfluent when their external auditory feedback is delayed by 200 ms, but not when it is completely masked by loud noise. In the latter condition, but not in the former one, the speaker’s attention can shift to the internal auditory feedback.
(return)
Levelt (1995) extensively discussed the issue of pre-articulatory monitoring: does a person, during normal spontaneous speech, check his or her words and sentences before speaking them out? Can the speaker detect speech errors or inappropriate wording in this way and suppress or correct them before speaking? The issue is theoretically relevant for two reasons. First, evidence of pre-articulatory monitoring would also evidence a ‘phonetic plan’ (presumed by Levelt), which would contradict the model proposed by Engelkamp and Rummer (1999), according to which not a phonetic plan but speaking programs (speech motor programs) control articulation (see Section 1.2.). The concept of speaking programs, however, is basic to the stuttering theory presented on this website; it allows us to say that a moment of stuttering is caused by the inhibition of a speaking program.
The second reason why my stuttering theory is inconsistent with the existence of pre-articulatory monitoring is the following: pre-articulatory monitoring implies that external and internal feedback loop work concurrently. My stuttering theory, in contrast, presupposes that external and internal auditory feedback are not available at the same time. For these to reasons, I claim that internal auditory feedback is not available when one’s own speech is heard externally, and that there is no pre-articulatory monitoring based on the internal feedback of a phonetic plan (as assumed by Levelt) during spontaneous speech. Here, a remark is necessary about different concepts of speech feedback. I distinguish between external and internal auditory feedback of speech; that is, not only the external but also the internal feedback of speech is in the auditory modality. We hear our voice internally during silent reading or thinking. By contrast. Levelt did not say that internal speech feedback is in the auditory modality. He possibly believed that the phonetic plan and its monitoring in the speech comprehension system (see Figure) would not take place in any sensory modality but as a computation in a neuronal ‘machine language’ . This view of the brain as a computer was popular at the time, but I think it’s fundamentally wrong. Levelt reasoned for the existence of pre-articulatory monitoring by referring to several experiments, in which participants spontaneously suppressed saying nonwords and taboo words, respectively (Baars, Motley, & MacKay, 1975; Motley, Camden, & Baars, 1982). Pre-articulatory monitoring also seems to be suggested by very quick error repairs that can hardly be based on external auditory feedback (Nooteboom & Quené, 2017; Seyfeddinipur, Kita, & Indefrey, 2008). But this behavior can be explained without pre-articulatory monitoring. Nozari, Dell, and Schwartz (2011) proposed and tested a model of speech errors detection prior to articulation not based on the internal feedback of a phonetic plan, but on conflict monitoring during speech production. Support for this view comes from EEG studies. A specific event-related potential, the error-related negativity, was identified in speech tasks, among others, which seems to be related to conflict monitoring (Ganushchak & Schiller, 2008; Ries et al., 2011; Trewartha & Philips, 2013). Pre-articulatory error detection is thus no evidence that internal auditory feedback was available. Undoubtedly, deliberate pre-articulatory monitoring is possible; we can pre-formulate a sentence internally before we speak it out. But this is nothing more than verbal thinking, and we don’t do so in spontaneous speech but only in situations, in which it is necessary to avoid saying something wrong, such as in exams or in political or commercial negotiations. Some stutterers behave so to avoid words with initial sounds on which they fear stuttering. But in normal spontaneous speech, we, don’t monitor and sanitize our words and sentences internally before speaking, and therefore, mistakes and self-corrections are not the exception but the rule in spontaneous speech. (return)